重塑Scoreboard机制,让CPU性能跃升!如何优化CPU性能?
核心要点
当今的人工智能加速器面临着深度流水线和复杂数据依赖等挑战。这种架构可实现精确的指令调度,且没有推测执行的开销。通过最大化指令发布时机并最大限度地减少无效功耗周期,确保了能源效率。当今的人工智能加速器,无论是为大型数据中心还是低功耗边缘设备所构建,都面临着一系列共同的挑战:深度流水线、复杂的数据依赖以及推测执行的高昂成本。这些问题在高频微处理器设计中早已为人熟知,工程师们必须不断在性能和正确性之间寻求平衡。流水线越深,指令级并行的机会就越大,但流水线冒险的风险也越高,特别是写后读(RAW)依赖。
20 世纪 70 年代出现并在 90 年代超标量繁荣时期得到改进的传统Scoreboard(记分板)架构,仅提供了部分解决方案。虽然能发挥作用,但它们难以随着现代流水线日益增长的复杂性而扩展。每增加一个阶段或执行通道,操作数比较的数量就会呈指数级增长,这会引入延迟,使得维持高时钟频率变得更加困难。
Scoreboard的核心功能是确定一条指令是否可以安全发布,这需要将正在执行的指令的目标操作数与等待发布的指令的源操作数进行比较。在深度或宽度较大的流水线中,这种逻辑很快就变成了一个组合逻辑难题。需着手解决的问题是:我们能否在不依赖复杂的关联查找或推测机制的情况下,准确地对操作数时序进行建模?
在笔者开发双行Scoreboard时,目标是在无线基带芯片中支持确定性时序,因为在这种芯片中,实时性保证至关重要,而且能源预算紧张。但随着时间的推移,这种架构被证明具有广泛的适用性。当今的工作负载,特别是人工智能推理引擎,通常要管理数千个同时进行的操作。在这些领域,传统的推测方法,如乱序执行,可能会带来能源成本和验证复杂性的问题,这在实时或边缘部署中是不可接受的。
笔者的方法则另辟蹊径,以可预测性和效率为基础。开发了一种双行Scoreboard架构,它通过周期精确的时序和基于移位寄存器的跟踪。重新构想了传统模型,在消除推测的同时,能够适应现代人工智能工作负载。它将时序逻辑分为每个架构寄存器的两个同步但独立的移位寄存器结构,确保了精确的指令调度,且没有推测开销。
Scoreboard机制—— 移位寄存器方法
可以把双行Scoreboard想象成一个传送带系统。每个寄存器都有两条轨道。上行轨道监控数据在流水线中的位置;下行轨道监控数据何时准备就绪。每个时钟周期,这些传送带上的标记都会移动一步,推进每条指令的时间线。
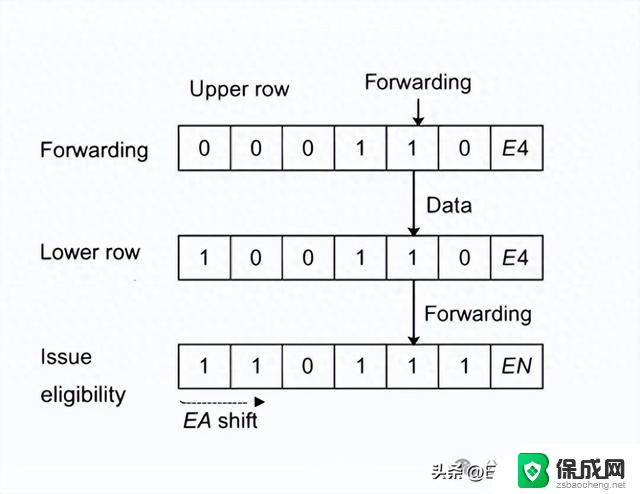
转发跟踪器—— 上行轨道:这一行作为移位寄存器运行,在流水线阶段之间移动一个单例“1”,精确跟踪将生成结果的指令的位置。这使得无需直接访问寄存器文件就能进行转发。
发布资格跟踪器—— 下行轨道:第二行独立地跟踪结果何时可用,使用一串从最早可用阶段开始的“1”。如果依赖的指令在数据准备好之前需要它,发布就会停滞。否则,就立即进行。
通过将操作数就绪状态与执行时序进行比较,Scoreboard使用以下公式做出简单直接的发布决策:
D = (EA – E) – EN + 1
其中:
E 是生产者指令的当前阶段EA 是结果首次可用的阶段EN 是消费者首次需要结果的阶段如果 D≤0,依赖的指令可以安全发布。如果 D>0,则必须等待。
例如,假设结果在 EA = E3 时可用,生产者当前处于 E2 阶段,消费者在 EN = E2 时需要它。那么:D = (3 – 2) – 2 + 1 = 0→该指令可以立即发布。这种简单的算术运算确保了确定性的执行时序,使该架构具有可扩展性和高效性。
集成与实现
每个架构寄存器都有自己的Scoreboard “页面”,其中包含上行和下行轨道。因此,Scoreboard是一种稀疏的、分布式结构,概念上是一个 3D 数组,按寄存器名称(深度)、流水线阶段(列)和逻辑类型(上行与下行轨道)进行索引。由于两行都与流水线时钟同步移位,因此不需要多周期仲裁或停滞传播。
寄存器文件本身也得到了简化,因为许多操作数从未到达那里。如果结果在产生后很快就被消耗,数据转发允许结果完全跳过寄存器文件。这在功耗和面积方面都有好处,特别是在寄存器文件写入端口成本高昂的小工艺节点中。
为何在今天仍有重要意义
笔者构建这个架构是为了解决一个极其具体的问题:如何在无线调制解调器中保证实时执行,在这种情况下,失败是绝不容许的。我的设计首次应用于 TI 的 OMAP 1710,它不仅为主要的 ARM+DSP 组合提供动力,还塑造了支持 GSM、GPRS 和 UMTS 的专用调制解调器流水线。
在调制解调器路径中,错过最后期限意味着数据包丢失,这不像丢失视频帧那样只是令人烦恼,而是至关重要的。因此,我专注于可预测的延迟、范围严格的内存和结构化的任务流程。这种源于调制解调器的蓝图,如今在人工智能和边缘芯片中焕发新生,在这些领域,功耗限制要求同样严格、确定性的执行。
对于边缘人工智能设备等功耗受限的环境,推测执行带来了一个独特的挑战:预测错误的指令所造成的无效功耗周期会迅速耗尽能源预算。人工智能推理工作负载通常要处理数千个并行操作,而不必要的推测会迫使计算单元花费电力执行最终会被丢弃的指令。双行Scoreboard的确定性调度消除了这个问题,确保只在恰好合适的时间发布必要的指令,在不牺牲性能的情况下最大限度地提高能源效率。
寄存器文件本身也得到了简化,因为许多操作数从未到达那里。如果结果在产生后很快就被消耗,数据转发允许结果完全跳过寄存器文件。在生产者和消费者指令的目标寄存器相同的情况下,生产者甚至可能根本不需要写回到寄存器文件,从而节省更多电力。这在功耗和面积方面都有好处,特别是在寄存器文件写入端口成本高昂的小工艺节点中。
这种转变延伸到了 RISC-V 生态系统,架构师们正在探索时序透明的设计,以避免推测执行带来的额外负担。无论是应用于人工智能推理、向量处理器还是特定领域的加速器,这种方法都能提供强大的冒险处理能力,同时不牺牲清晰度、效率或正确性。
结论—— 架构思维的转变
几十年来,微处理器架构师一直在平衡性能和正确性,应对深度流水线和复杂指令依赖带来的挑战。传统的乱序执行机制依靠动态调度和重排序缓冲区,通过尽快执行独立指令(无论其原始顺序如何)来最大限度地提高性能。虽然这种方法在利用指令级并行性方面很有效,但它带来了能源开销、更高的复杂性和验证挑战,尤其是在深度流水线中。相比之下,双行Scoreboard提供了精确的、周期精确的时序,不需要推测性重排序。它不是不可预测地重新排列指令,而是在发布前确保可用性,在保持吞吐量的同时减少控制开销。
事后看来,Scoreboard不仅仅是一种控制机制,更是一种思考执行时序的新方式。它不是预测未来,而是确保系统精确地满足未来—— 这一原则在今天仍然像它最初构想时一样具有现实意义。随着现代计算向更具确定性和能效的架构发展,将时间作为首要的架构概念已不再只是理想,而是必不可少的。
重塑Scoreboard机制,让CPU性能跃升!如何优化CPU性能?相关教程
-
 AMD AGESA 1.2.0.2 BIOS优化CPU核间延迟,多核性能提升超一倍
AMD AGESA 1.2.0.2 BIOS优化CPU核间延迟,多核性能提升超一倍2024-09-18
-
 AMD 针对 Linux 发布 3D V-Cache 性能优化驱动程序,提升显卡性能
AMD 针对 Linux 发布 3D V-Cache 性能优化驱动程序,提升显卡性能2024-10-10
-
 6大国产CPU,谁性能最强,谁最能自主可控?——国产CPU性能对比及自主可控性评测
6大国产CPU,谁性能最强,谁最能自主可控?——国产CPU性能对比及自主可控性评测2024-05-09
-
 CPU频率现在重要么?如何正确选择CPU性能?
CPU频率现在重要么?如何正确选择CPU性能?2024-10-06
-
 个人电脑CPU和个人手机CPU之间的区别及性能对比
个人电脑CPU和个人手机CPU之间的区别及性能对比2024-04-21
-
 win11怎样设置高性能 Win11怎么设置CPU高性能模式
win11怎样设置高性能 Win11怎么设置CPU高性能模式2024-09-17
- 最新的服务器 CPU 天梯图:2021年最强CPU性能排名揭晓
- 高通发布搭载Oryon CPU的Snapdragon 8 Elite芯片 GPU性能提升40%详细介绍
- CPU性能PK!Ryzen 7 8700G VS Ryzen 7 7800X3D,实测出炉,性能对比谁更强?
- 如何正确安装独立显卡,让台式电脑性能提升?
- 微软年内第二次大裁员,或波及9000人,全面解读微软裁员背后原因和影响
- AMD压倒性优势!CPU销量周销量占比93%,前十无Intel身影
- 微软宣布全球裁员9000人,占员工总数不到4%,影响如何?
- 最高涨幅20%:微软上调本地服务器产品价格,企业如何应对?
- 微软AI表现拉跨 竟强制员工使用,员工反感情绪高涨
- AMD发布25.6.3驱动:支持怪物猎人:荒野GTA5增强版,新增FSR 4技术
热门推荐
新闻资讯推荐
- 1 AMD压倒性优势!CPU销量周销量占比93%,前十无Intel身影
- 2 英伟达 RTX 5070 SUPER 显卡技术解析:性能、功能及价格一览
- 3 AMD Radeon RX 9070 XT供不应求,其余RDNA 4产品表现平淡,需求旺盛!
- 4 Win11与Win10电脑性能对比:新旧硬件到底有多快?
- 5 微软Windows发布新功能:快速电脑恢复,告别蓝屏,迎来黑屏优化
- 6 微软Win11夏末意外重启界面更新:适配24H2版本最新功能
- 7 微软发布收紧内核运行权限的Windows内测版,避免全球大宕机重现
- 8 不是任何CPU都能流畅“吃鸡”看这地方,教你如何选择适合的游戏主机
- 9 无主之地4配置要求8核CPU,超半数玩家无法达标
- 10 NVIDIA 她力量:实习生特辑之多元·成长·突破-领略新一代女性实习生的成长历程
win10系统推荐
系统教程推荐
- 1 倒数日怎么设置在桌面 倒数日桌面显示方法
- 2 如何让windows电脑常亮 怎样让笔记本屏幕保持长时间亮着
- 3 ie8浏览器如何兼容 IE浏览器兼容模式设置方法
- 4 w10如何关闭杀毒 Windows10系统如何关闭自带杀毒软件
- 5 笔记本电脑哪个键代表鼠标右键 用键盘代替鼠标右键的方法
- 6 怎样查看windows激活状态 win10系统激活状态查看步骤
- 7 电脑怎么连接有线打印机设备 电脑连接打印机的设置方法
- 8 win10鼠标单击变双击了 win10系统鼠标单击变双击原因
- 9 iphone怎么将视频设置动态壁纸 iPhone动态壁纸视频设置教程
- 10 电脑锁屏怎么办 电脑自动锁屏怎么取消